Что такое Load Average. Определяем среднюю нагрузку на сервер
Верная оценка нагрузки системы складывает характеристику производительности и работоспособности системы в целом. Что есть важной деталью при мониторинге сервера.
Load Average (LA, средняя нагрузка) - это средняя мера нагрузки, отображается в количестве процессов, которые находятся в состоянии выполнения или в состоянии ожидания ресурсов за интервал времени 1, 5 и 15 минут. Так как нагрузка колеблется быстро из-за кратковременных процессов, более полезно смотреть на среднюю нагрузку с течением времени, что дает лучший обзор. Эти цифры могут рассказать много о том, насколько заняты процессор, диск и другие элементы системы.
Самый простой способ увидеть среднее значение нагрузки на сервере с ОС Linux - это запустить команду uptime в терминале. Команда uptime на выводе отображает текущее время, продолжительность работы системы, количество пользователей, вошедших в систему, и средние значения нагрузки системы за последние 1, 5 и 15 минут.
![]()
Note: за пример взята нагрузка на сервере нашего минимального тарифа VPS с 1 ядром.
Получив 3 значения за разные промежутки времени можно понять состояние системы и проанализировать динамику нагрузки, если все полученные значения равны 0 - значит система в режиме ожидания, если значения увеличиваются (для 1, 5 и 15 минут соответственно) - нагрузка в системе растет, уменьшаются - нагрузка падает.
Эти значения мало что говорят без количества выполняемых и общих процессов в системе. Посмотреть общее количество активных и ожидающих процессов можно командой top. Также эта команда выведет среднее значение по нагрузке (как и команда uptime), самые тяжелые процессы в порядке спадания и другую важную информацию.
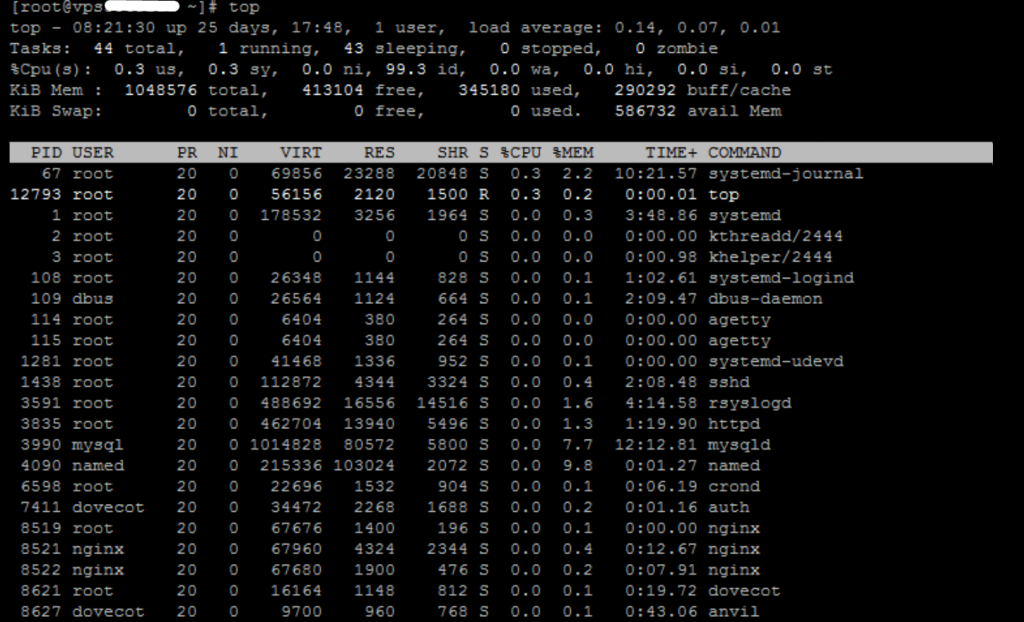
Или же как вариант, использовать команду. Где после выполнения команды, возвращаются значения, где первые три поля содержат среднюю нагрузку, в 4 поле перед слешем идет количество запущенных процессов, после слеша сумма всех процессов в системе в текущее время, и в конце выведен индикатор процесса. Как можно уже видеть, существует много способов проверить среднюю нагрузку в системе.
![]()
Для просмотра всех процессов в системе вводим в терминал команду ps auxfS.
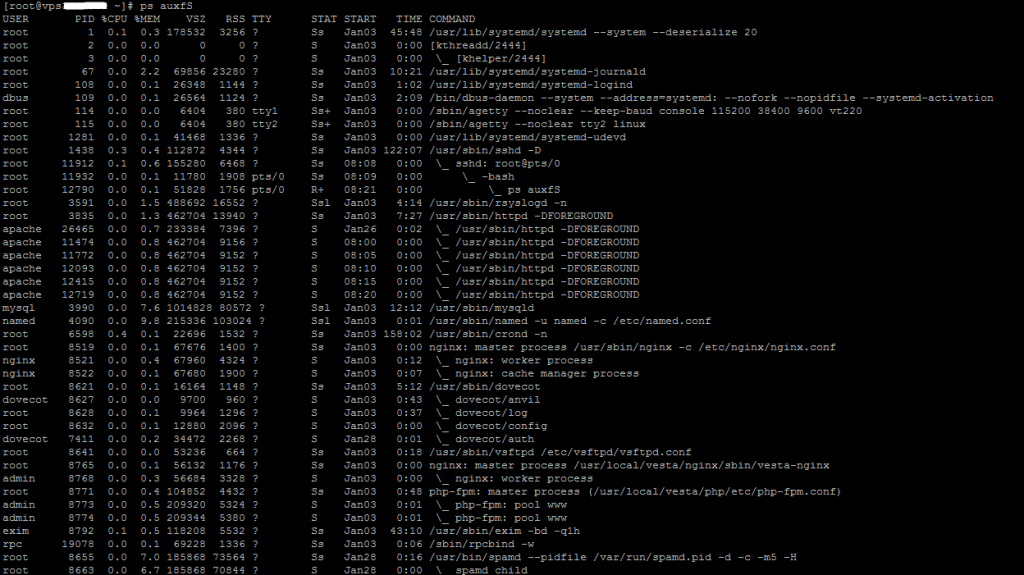
Если желаете закрыть ненужный процесс (например, cron) для освобождения ресурсов вбиваем в консоль команду kill после чего ставим PID процесса (индикатор процесса). PID процесса см. сверху на скрине во втором столбике. Это действие нужно выполнять с большой осторожностью и понимать, какой процесс за что отвечает.
![]()
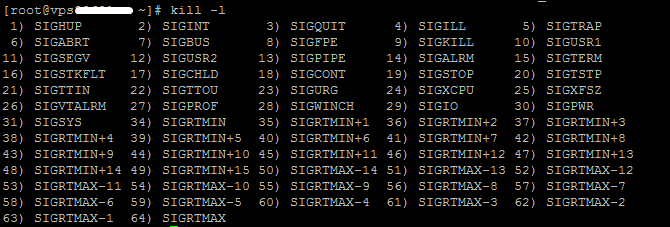
Если процесс не остановлен попробуйте использовать сигнал SIGKILL, под номером 9, он должен полностью уничтожить процесс.
![]()
Номера всех сигналов можно узнать с помощью команды kill -l.
Чтобы правильно интерпретировать среднее значение нагрузки нужно знать сколько ядер имеет процессор. Так как правило, для 1 ядерного процессора при его использовании на 100% это будет отображаться по средней нагрузки как 1.00, на двухъядерном процессоре полная занятость процессора будет выдаваться по нагрузке как 2.00, для 3-х ядер как 3.00 и так далее. То-есть если мы имеем нагрузку 0,01 для 1 ядра следует, что 99% процессорного времени процессор находится в простое. Если для 1 ядерного процессора среднее значение нагрузки больше 1, например равно 1,5, этот факт определяет, что количество текущих процессов превышает допустимое количество запущенных процессов, которые процессор может обрабатывать одновременно, и процессы ожидали 50% процессорного времени в очереди до своего выполнения. Чем значение по нагрузке ниже тем конечно лучше.
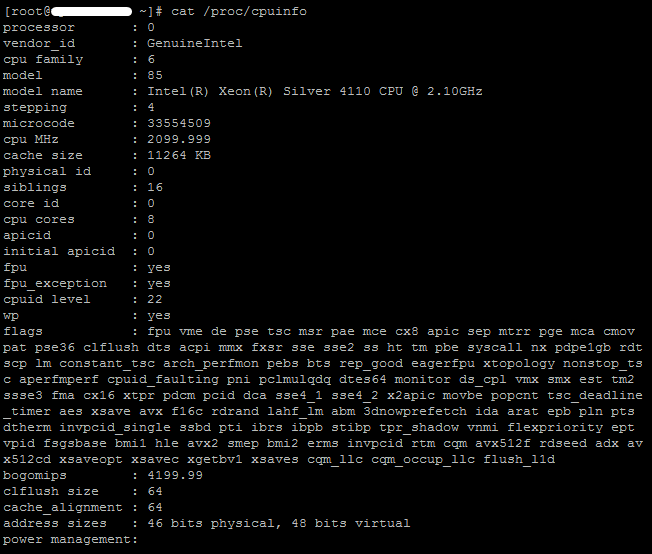
Узнать количество ядер на сервер можно командой grep 'model name' /proc/cpuinfo | wc -l, на выводе получите количество ядер на вашем сервере. Как видим, на тарифе VPS Мини мы имеет сервер с 1 ядром.
![]()
Полную информацию касательно процессора можно узнать используя команду cat /proc/cpuinfo.
В системе может быть много скачков в течение более длительного периода времени, например, при запуске некоторых неисправных процессов, при выполнении заданий cron, когда за короткий промежуток времени подключается больше пользователей или когда сервер подвергается атакам, поэтому лучше не опираться только на uptime или top команды, а дополнительно полагаться на инструменты мониторинга, таких как Zabbix, Nagios, Monit, которые регистрируют на активность процессора и памяти в долгосрочной перспективе. Больше информации касательно систем мониторинга серверов можно узнать в нашей статье здесь.
Специалисты ГиперХост всегда рады предоставить помощь и консультирование всем нашим клиентам касательно вопросов по нагрузке на сервере.






