DeepSeek - аналог ChatGPT чи його «вбивця»?
У січні поточного року китайська компанія з міста Ханчжоу, що спеціалізується в галузі розробки штучного інтелекту (ШІ) представила версію R1 моделі ШІ під назвою DeepSeek. Ця новина буквально вразила світ технологічної індустрії, що найяскравіше проявилося в різкому падінні акцій виробників графічних процесорів (GPU) на фондових ринках, чого ніколи раніше не фіксували у США. У чому ж феномен «китайського дива» і наскільки серйозними можуть бути наслідки?
У чому секрет успіху DeepSeek
Представлена китайськими інженерами модель ШІ є різновидом великої мовної моделі LLM (Large Language Model), яка використовується для побудови нейронних мереж для застосунків ШІ. На їхній основі можна будувати системи ШІ для впровадження в будь-яку галузь знань - IT, автоматику, лінгвістику, фінанси тощо.
Факт появи чергової моделі ШІ сам по собі не є підставою для ажіотажу, адже щороку у світі їх з'являються сотні штук, і зазвичай на це звертають увагу лише вузькі спеціалісти. Але тільки не цього разу.
Перша версія мовної моделі під назвою DeepSeek Coder побачила світ зовсім нещодавно - у листопаді 2023 року і була орієнтована на розв'язання задач із програмування. Тоді на неї мало хто звернув увагу. Після цього з'явилися версії VL (березень 2024 р.) і V2 у травні того ж року. Останній варіант виявився настільки успішним, що призвів до обвалу цін на ринку китайських брендів, що працюють у сфері IT - Alibaba, Baidu, Tencent і багатьох інших.
У листопаді минулого року вийшов DeepSeek V3, який здійснив прорив у швидкості виведення відповідей порівняно з більш ранніми версіями. Січнева 2025 року версія DeepSeek R1 була побудована на основі V3 і увібрала в себе її найкращі риси. Її основним завданням стало розв'язання задач «на логіку» і виконання математичних розрахунків у реальному режимі часу.
Проєкт DeepSeek фінансувався і фінансується винятково з фонду китайської інвестиційної компанії High-Flyer, оціненої приблизно в $8 млрд, власником якої є приватний підприємець Лян Веньфен. Близько року тому, після виходу першої версії моделі, він дав одне з перших своїх інтерв'ю, де сформулював основні тези своєї концепції «нової революції» у світі IT.
Ось деякі з його тез: «наша домінантна стратегія - відкритий вихідний код, а не комерціалізація», «ми робимо наголос на молодих місцевих талантах, а не на досвідчених або зарубіжних спеціалістах», «ми не дивимося на те, вигідно це або невигідно, а лише на те, правильно це або неправильно», «ми хочемо зламати традиційну думку, що тільки американці здатні до розроблення фундаментальних основ інновацій, а ми можемо працювати лише з інноваціями застосунків».
 Генеральний директор Лян Веньфен (праворуч) під час інтерв'ю восени 2023 року.
Генеральний директор Лян Веньфен (праворуч) під час інтерв'ю восени 2023 року.
Очевидно, що цей сорокарічний розробник і керівник проекту має амбіції претендувати на щось більше, ніж просто створення «китайського дива». До речі, за словами деяких із підлеглих Лян Веньфена, він не схожий на «класичного боса», а «скоріше на колегу з наукових пошуків».
Китайські інженери на своєму сайті відкрили за допомогою API вільний доступ до LLM. Також було представлено робочий варіант чату на базі DeepSeek R1 і детальну технічну документацію до нової LLM з усіма економічними розрахунками щодо ефективності її використання.
За результатами вивчення представлених документів стало зрозуміло, що нововведення на кілька сотень відсотків (!) ефективніше за використовувані нині LLM для застосунків ШІ.
Це особливо важливо для наукомісткої галузі ШІ, яка вимагає великих капіталовкладень на всіх етапах технологічного циклу - вивчення, розробки, впровадження та експлуатації.
Для об'єктивного оцінювання ефективності того чи іншого технологічного рішення або IT-продукту необхідно мати результати за двома його основними показниками - продуктивністю та сумою загальних витрат. Тільки на підставі цих показників можна робити остаточні висновки про їхню ефективність. Розглянемо ці показники, спираючись на зазначені вище документи.
Продуктивність
Китайська сторона представила результати проведених тестів для своїх моделей DeepSeek версій R1 (січень 2025р.) і V3 (листопад 2024р.), а також новітніх моделей компанії OpenAI, Inc версій o1 1217 і o1 mini, розроблених у листопаді 2024р.
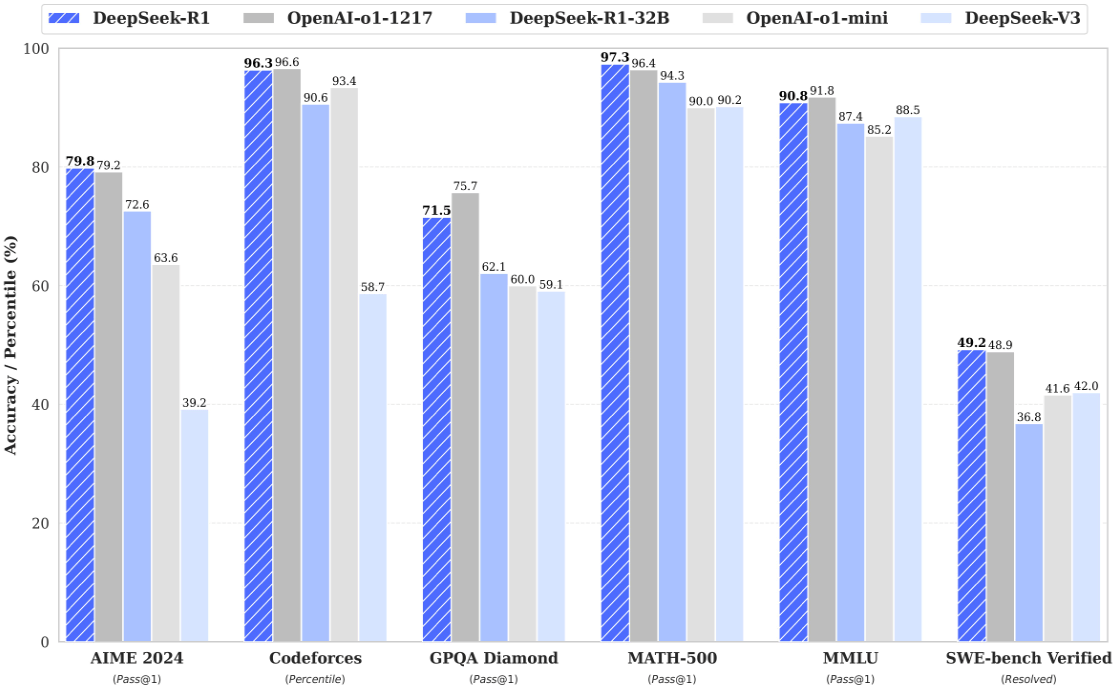
Тести проводилися для різних напрямів розвитку штучного інтелекту за відомими в усьому світі методиками:
- AIME 2024 - тест на продуктивність;
- Codeforces - змагальне програмування;
- GPQA Diamond - перевірка знань у галузі фізики, хімії та біології;
- MATH-500 - математичний тест із розв'язання задач на міркування;
- MMLU - перевірка загальних знань про світ;
- SWE-bench Verified - перевірка здатності виправляти баги в Інтернет-проектах, розміщених у GitHub-репозиторіях.
Результати тестування зведемо в Таблицю 1:
Таблиця 1. Результати тестування DeepSeek V3, R1 і їхніх аналогів.
| Вид перевірки |
DeepSeek-R1 (%) |
OpenAI o1-1217 (%) |
Піідсумки |
|
AIME 2024 |
79.8 |
79.2 |
DeepSeek-R1 – найкраща у вирішенні математичних задач |
|
Codeforces |
96.3 |
96.6 |
OpenAI-o1-1217 – найкраща у змагальному програмуванні |
|
GPQA Diamond |
71.5 |
75.7 |
OpenAI-o1-1217 перемогла в загальній продуктивності |
|
MATH-500 |
97.3 |
96.4 |
DeepSeek-R1 перемогла в темі математичних міркувань |
|
MMLU |
90.8 |
91.8 |
OpenAI-o1-1217 показала найкращі результати в темі загальних знань |
|
SWE-bench Verified |
49.2 |
48.9 |
DeepSeek-R1 перемогла в темі розробка ПЗ |
З результатів тестування видно, що остання версія китайської LLM у 50% тестів перевершує своїх конкурентів. Слід зазначити, що LLM o1 1217 і o1 mini від компанії OpenAI, Inc. є основою для побудови інтелектуального чат-бота ChatGPT, який «підірвав» світ своєю «інтелектуальністю» і широким спектром застосування.
Сума загальних витрат
У документації від виробника наводяться дані про загальні витрати на підготовку і введення в експлуатацію базової версії DeepSeek V3, виражені в GPU-годинах і їхньому грошовому еквіваленті в USD. Було застосовано GPU-процесори компанії Nvidia моделі H800. Тут приймалося, що 1 година роботи GPU коштує $2. Загальні результати з розбивкою за кожним видом витрат зведені нами до Таблиці 2 у тому самому форматі, в якому вони були представлені самим виробником.
Таблиця 2. Загальні витрати на підготовку і введення в експлуатацію моделі DeepSeek V3.
| Од. виміру витрат |
Попереднє навчання моделі |
Розширення контексту |
Подальше підстроювання |
Всього затрат |
|
H800 GPU-часы |
2664K |
119K |
5K |
2788K |
|
USD |
$5,328M |
0,238M |
0,01M |
5,576M |
Таким чином, загальна підготовка базової моделі V3 і її введення в експлуатацію обійшлися виробнику в $5,576 млн. При цьому було витрачено 2,788 млн. GPU-годин. Час підготовки - в межах двох місяців.
Якщо порівнювати з конкурентами витрати за кількістю годин, то підготовка моделей того ж рівня компанією Meta AI обійшлася останній у 30,8 млн. GPU-годин, що приблизно в 10 (!) разів більше.
Якщо порівнювати з найближчими конкурентами витрати в грошовому еквіваленті, то, наприклад, загальні інвестиції компанії OpenAI, Inc у підготовку і випуск моделі o1 1217 оцінюються приблизно в $6 млрд, що на кілька порядків вище.
З наведених даних можна зробити висновок, що ефективність представленої LLM DeepSeek порівняно з наявними аналогами просто зашкалює. Тобто, це дійсно технологічний прорив, і дуже серйозний. Саме це стало причиною обвалу цін на фондових біржах і «шокувало» компанії монополістів - виробників GPU і моделей ШІ.
Чим DeepSeek унікальний від інших ШІ-моделей
Унікальність DeepSeek полягає у використанні низки «нестандартних» рішень під час побудови конфігурації LLM і розроблення нових алгоритмів її обробки / навчання. Виділимо основні з них:
Мультимодальність (Multimodality) архітектури мовної моделі. Забезпечується завдяки застосуванню технології MoE (Mixture-of-Experts), суть якої полягає в «розбивці» загального обчислювального простору моделі на окремі підмережі або «експерти», кожен з яких спеціалізується у своїй предметній області. Така архітектура дає змогу підвищити продуктивність обчислень завдяки переспрямуванню вхідного потоку даних (задачі) тим «експертам», які «в темі», і тому здатні швидко розв'язати задачу і видати відповідь.
Ми описали підсумкову конфігурацію моделі, отриману в результаті застосування зазначеної технології, тобто, коли модель уже навчена. Для того, щоб отримати такий результат, потрібно створити умови для навчання кожного з «експертів». Причому, їхнє навчання має відбуватися постійно, навіть коли вони просто відповідають на поставлені запитання. І що довше триває процес навчання, то «розумнішими» стають «експерти», а отже, вищою продуктивність моделі загалом.
Про можливості застосування MoE в нейронних мережах почали говорити ще з 90-х років минулого століття, наприклад, у роботах «Hierarchies of adaptive experts» і «Hierarchical Mixtures of Experts and the EM Algorithm» . Ба більше, MoE кілька років тому почали розглядати як можливий ефективний засіб для глибокого навчання моделей ШІ. Перша наукова стаття про це під назвою «Learning Factored Representations in a Deep Mixture of Experts» була опублікована 2013 року. Однак широкого практичного застосування як засобу навчання технологія поки що не отримала, якщо, звісно, не брати до уваги DeepSeek.
Використання методів змішаного навчання на основі самонавчання. Для навчання моделі тут використовується два підходи - самонавчання і «тонке налаштування». Самонавчання або навчання без вчителя є одним із видів машинного навчання, за якого мережа, що навчається, вчиться самостійно без «підказок» ззовні. У цьому разі системі не ставлять правильних відповідей для розв'язання завдань, і тому вона має знаходити їх самостійно. Такий підхід найближчий до принципів навчання або самонавчання біологічних систем, коли відповідь на будь-яке питання заздалегідь невідома, а її потрібно знайти «своїми силами».
Також перевагою алгоритму є вищий рівень продуктивності, оскільки тут не потрібно виконувати ресурсовитратні операції порівняння з наперед визначеними відповідями, оскільки система шукатиме їх самостійно. Теоретичні засади розглянутого алгоритму ще понад 20 років тому були закладені відомим дослідником у галузі нейронних мереж Кохоненом і багатьма іншими дослідниками в галузі ШІ.
Метод «тонкого налаштування» є додатковим і, як правило, використовується для уточнення «знань» уже навченої системи. Алгоритм особливо ефективний для «вузьких» галузей знань і не вимагає великих ресурсних витрат. Навчання відбувається шляхом введення нової групи вагових коефіцієнтів, які пов'язують останній шар моделі з вихідними даними наступного завдання. Ця нова група коефіцієнтів і підлягає вивченню, залишаючи осторонь вихідні, вже вивчені коефіцієнти. Хоча і вони в процесі навчання можуть періодично модифікуватися системою. Цей метод докладно описано 2023 року в роботі Деніела Джурафскі зі Стенфордського Університету.
Використання технології MLA (Multi-head Latent Attention). Технологія є альтернативою відомої технології MHA (Multi-Head Attention) і дає змогу оптимізувати використовувану пам'ять кешу (KV) під час виконання обчислень у нейронних мережах. Це досягається завдяки збільшенню кількості паралельно оброблюваних потоків порівняно з традиційною технологією MHA, що, зрештою, призводить до підвищення продуктивності моделі та збільшення її масштабованості.
Порівняння зазначених технологій під час організації обчислень у малій нейронній мережі було зроблено в нещодавно опублікованій роботі одного з наукових співробітників Riot Games зі США. У ній він припустив можливість ефективності MLA в разі її застосування у великих мережах, що і було зроблено в DeepSeek.
Порівняння DeepSeek і ChatGPT
На базі LLM-моделей можуть створюватися всілякі додатки ШІ, одним з яких є інтелектуальний чат-бот. Перший такий чат-бот під назвою ChatGPT був випущений американською компанією OpenAI, Inc ще восени 2022 року. У його назві присутня назва версії LLM-моделі, розробленої тією ж компанією. Пізніше компанія змінила порядок формування назв версій, внаслідок чого з'явилися o1 1217 та її «усічений» варіант o1 mini, про які вже йшлося вище.
Одночасно з виходом DeepSeek R1, розробники моделі представили світові конкуруючий чат-бот, який за зовнішніми ознаками аналогічний проекту ChatGPT, але має своє «внутрішнє наповнення» у вигляді нової конфігурації нейронної мережі та алгоритмів її обробки, про що йшлося вище.
Деякими незалежними експертами було проведено низку тестів нового чат-бота, під час яких з'ясувалося, що загалом він «адекватний» і його «здібності» приблизно відповідають результатам тестів, наведених нами раніше. Так, DeepSeek відмінно справляється з розв'язанням математичних задач на міркування, а також показує хороші результати з програмування.
Серед недоліків бота багато експертів виділяють його певну упередженість у деяких політичних питаннях, що стосуються КНР. Наприклад, на запитання про приналежність Тайваню, бот «намагався» взагалі не відповідати або «викладав» відповідь у розлогих висловах, що загалом відповідало політичному баченню цього питання чинною владою КНР. В іншому ж бот давав цілком задовільні відповіді на поставлені експертами запитання.
Також було відзначено як недолік відсутність деяких додаткових функцій, які вже присутні в ChatGPT, наприклад, це стосується підтримки голосу та інших кейсів.
Однак, для об'єктивної оцінки чат-ботів, що конкурують між собою, слід скористатися аналізом порівняльної характеристики LLM-моделей, на базі яких вони побудовані. Тільки в цьому разі можна отримати об'єктивний висновок, що спирається на науковий підхід.
У Таблиці 3 наведено приблизні порівняльні характеристики їхніх моделей.
Таблиця 3. Порівняння характеристик LLM-моделей чат-ботів ChatGPT і DeepSeek.
|
Показник |
ChatGPT |
DeepSeek |
|
Генеративний трансформер |
Так |
Так |
|
Мультимодальність |
– |
Так. За рахунок підмереж - «експертів» |
|
Оптимізація KV |
Невідомо |
Так |
|
Технологія MoE |
– |
Підтримується |
|
Тип навчання |
Змішане з упором на «навчання з учителем» |
Змішане на підставі самонавчання |
|
Дані для навчання |
Великі закриті набори |
Відкриті набори даних |
|
Обробка даних |
В одному вич. просторі |
Розбивка на завдання між різними підмережами |
|
Универсальність |
Так. Більше підходить для загальних завдань |
Ні. Орієнтована на конкретні завдання |
|
Розподіл вич навантаження |
Відсутні механізми |
Оптимізовано між підмережами |
|
Прогнозування виведення |
Послідовне |
Паралельне |
|
Швидкість виведення результату |
Залежить від типу запиту |
Висока завжди |
|
Прозорість |
Обмежений доступ до ресурсів |
Відкритий вихідний код |
|
Модель безпеки |
Централізована високонадійна |
Децентралізована з підтримкою приватності |
|
Вартість використання на 1 млн. токенів, $ |
60 |
2,19 |
|
Тип ліцензії |
Пропрієтарна |
Вільна (Open Weights & MIT License) |
Можна переконатися, що за багатьма показниками внутрішньої архітектури та підходами до обробки даних моделі різняться, незважаючи на близькі показники результатів їхньої роботи. Ба більше, їхня відмінність лежить у глибинній площині структури LLM-мережі. Модель ChatGPT є яскравим прикладом централізованої повністю закритої системи обробки інформації, в той час, як DeepSeek використовує всі переваги децентралізації та відкритості - рівномірний розподіл навантаження, низька вартість, висока продуктивність, відкритий код і можливість модифікації структури. Усе це робить DeepSeek більш перспективною моделлю, що відповідає віянням часу.
Яку небезпеку несе DeepSeek
З історії добре відомо, що будь-яке технічне нововведення несе в собі прогрес для людства і водночас занепад для тих, хто жив і продовжує жити по-старому. І DeepSeek тут не виняток. Саме він з'явився тим рушієм, який змусить йти вперед абсолютно всіх, хто працює в галузі ШІ, починаючи від розробників моделей і закінчуючи виробниками GPU-чіпів. І цей процес уже почався, хоча минуло лише кілька днів після презентації. Хтось змінить методологію розробки і виробництва продуктів ШІ, а хтось скоротиться або збанкрутує. І це нормально. Також продовжиться знецінення всіх наукомістких Інтернет-проектів і блокчейн тут не виняток. Однозначно, «крипта» «піде вниз» і цей процес уже почався, судячи з її поточної вартості.
Користь для людства незабаром проявиться в широкому впровадженні порівняно дешевих систем і механізмів, побудованих на основі ШІ, оскільки монополія на «дорогі» моделі практично вже закінчилася, а тому будь-яка пересічна IT-компанія зможе створювати такі «дива техніки», як роботи-контролери, які розмовляють, автопілоти для всіх засобів пересування і багато іншого.
Що ж стосується оцінки того, наскільки широке впровадження ШІ відіб'ється на кожній людині, то давайте залишимо це філософам, які років через сто, можливо, знайдуть на це правильну відповідь.
.jpg)
.jpg)




