Що таке Вебархів (WebArchive) - чи реально відновити свій сайт з архіву
Нерідко трапляються ситуації, коли необхідно отримати застарілу версію сайту, наприклад, для потреб SEO-оптимізації або в разі пошкодження чи випадкового видалення веб-сторінки ресурсу. На цей випадок в мережі можна отримати пораду скористатися можливостями всесвітньо відомого сервісу WebArchive, який, як прийнято вважати, зберігає поточні версії всіх сайтів разом з усіма попередніми змінами. Іноді це дійсно може допомогти відновити втрачені дані, наприклад, вміст видаленої HTML-сторінки. Однак у багатьох інших випадках цей спосіб може не підійти, оскільки WebArchive зберігає лише миттєві знімки веб-сторінок сайтів, які не придатні для їх повноцінного відновлення. У зв'язку з цим, розглянемо можливості сервісу з відновлення втрачених даних, а також його обмеження.
Що таке Вебархів (WebArchive)
Веб-архів сайтів або Web Archive – це один з основних напрямків діяльності американської некомерційної організації Internet Archive щодо збереження історії Інтернет-мережі.
Проект реалізований на базі онлайн-сервісу Wayback Machine, що перекладається як Машина часу, створеного на базі мов Java і Python. Він забезпечує виконання двох основних завдань:
- Збір і зберігання знімків веб-сторінок з усієї мережі;
- Надання загальнодоступного інтерфейсу для доступу до збережених даних.
Web Archive не є традиційним хостингом або майданчиком для зберігання бекапів (backup), оскільки бекапи сайтів, як такі, ним не створюються, а лише моментальні знімки або знімки (snapshot) їх візуальної частини. Це дозволяє згодом відтворити видиму частину веб-ресурсу, що і було основною метою творців проекту.
До листопада 2025 року сервісом було каталогізовано та збережено колекцію веб-сторінок, що складалася з понад 1 трильйона примірників. І цей процес ніколи не припиняється, за винятком рідкісних періодів, пов'язаних з відновленням сервісу після хакерських атак, як, наприклад, було в жовтні 2024 року під час тривалої DDoS-атаки.
Як WebArchive зберігає сторінки сайтів
Поповнення веб-архіву здійснюється веб-краулерами або ботами, що входять до складу Wayback Machine, які працюють за аналогією з пошуковими роботами. Потрапивши на чергову веб-сторінку, вони послідовно обходять всі гіперпосилання, що знаходяться на ній, формуючи при цьому мережу доступних веб-вузлів для поповнення колекції архіву. Робот зупиняється тільки в разі перевищення встановленого ліміту.
Відскановані роботами копії веб-сторінок автоматично конвертуються у файли формату WARC (Web ARChive) розміром 100 МБ і зберігаються на серверах Internet Archive, розміщених у США, Єгипті та Нідерландах. Після цього архівні знімки веб-ресурсів стають доступними через інтерфейс Wayback Machine у форматі HTML з підтримкою технологій JavaScript (інтерактивність) і CSS (стилі сторінок).
Ініціювати процес збереження веб-сторінок ресурсу може і звичайний користувач мережі, ввівши в спеціальній формі на головній сторінці сервісу адресу сайту, як, наприклад, показано нижче на скріншоті. У цьому випадку URL ресурсу буде збережений системою і згодом використаний роботом для занесення сайту в архів
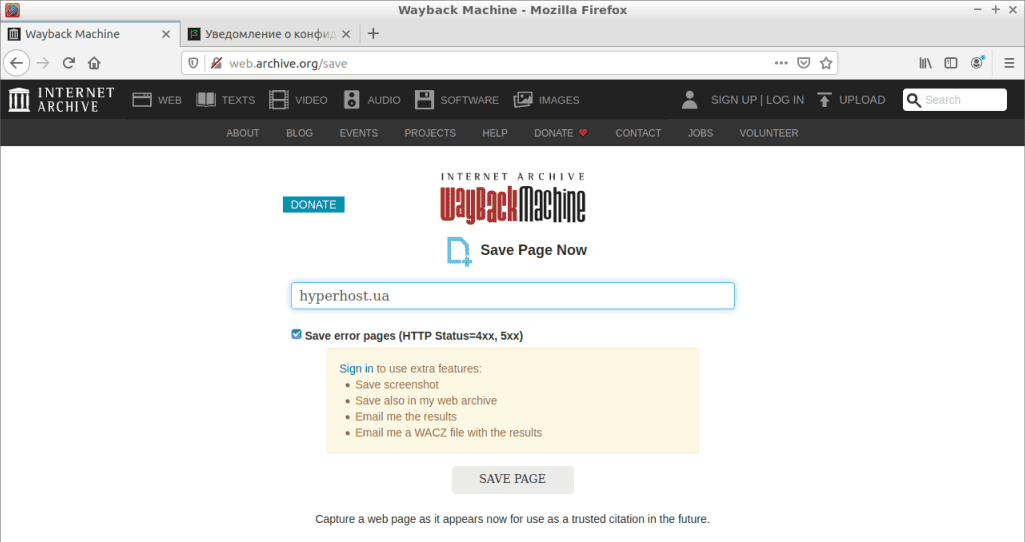
Як переглянути стару версію сайту через WebArchive
Чудовою особливістю сервісу є фіксація в загальнодоступній базі ланцюжка версій одного і того ж сайту, що дозволяє згодом використовувати цю інформацію в різних цілях, наприклад, для вдосконалення дизайну, аналізу дій конкурентів, SEO-оптимізації, відновлення даних і в багатьох інших випадках.
Щоб переглянути стару версію збереженого в базі сервісу веб-ресурсу, потрібно зайти на головну сторінку сервісу Wayback Machine і в рядку пошуку, розташованому під головним меню сторінки, ввести адресу потрібного ресурсу і натиснути Enter (див. скріншот).
При цьому ініціюється завантаження сторінки сервісу за обраним ресурсом, на якій буде виведений графік архівування сайту за весь період його «життя», а також календар створення копій для обраного сайту. У верхній частині завантаженої сторінки знаходиться кілька функціональних вкладок: Календар, Колекції, Зміни, Підсумкова інформація, Карта сайту і URLs (див. скріншот). Розглянемо призначення цих вкладок докладніше.
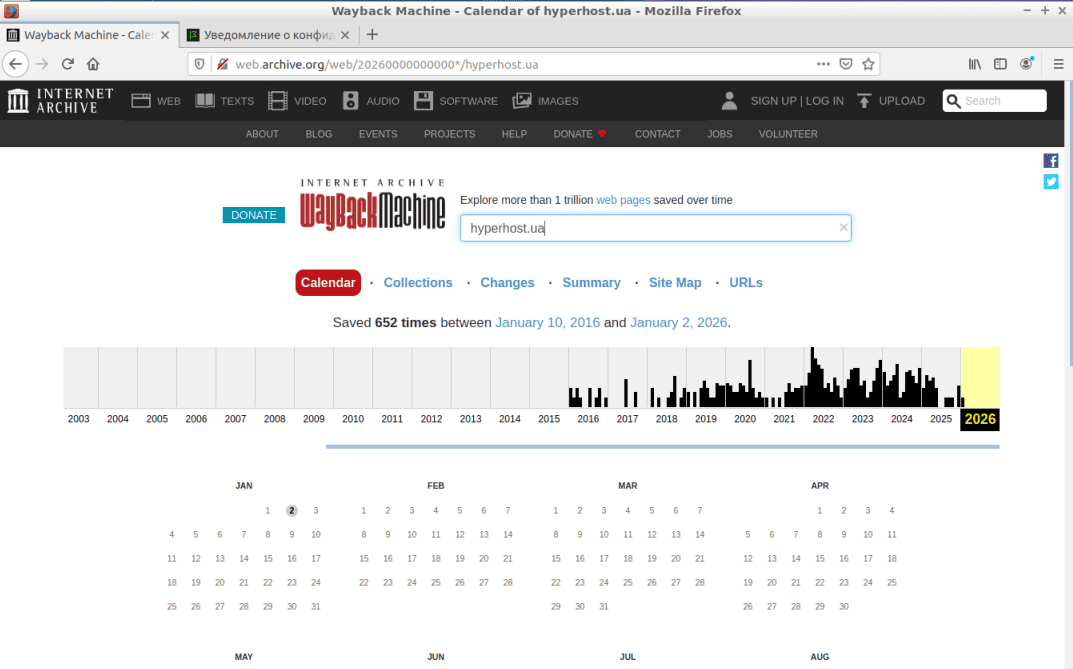
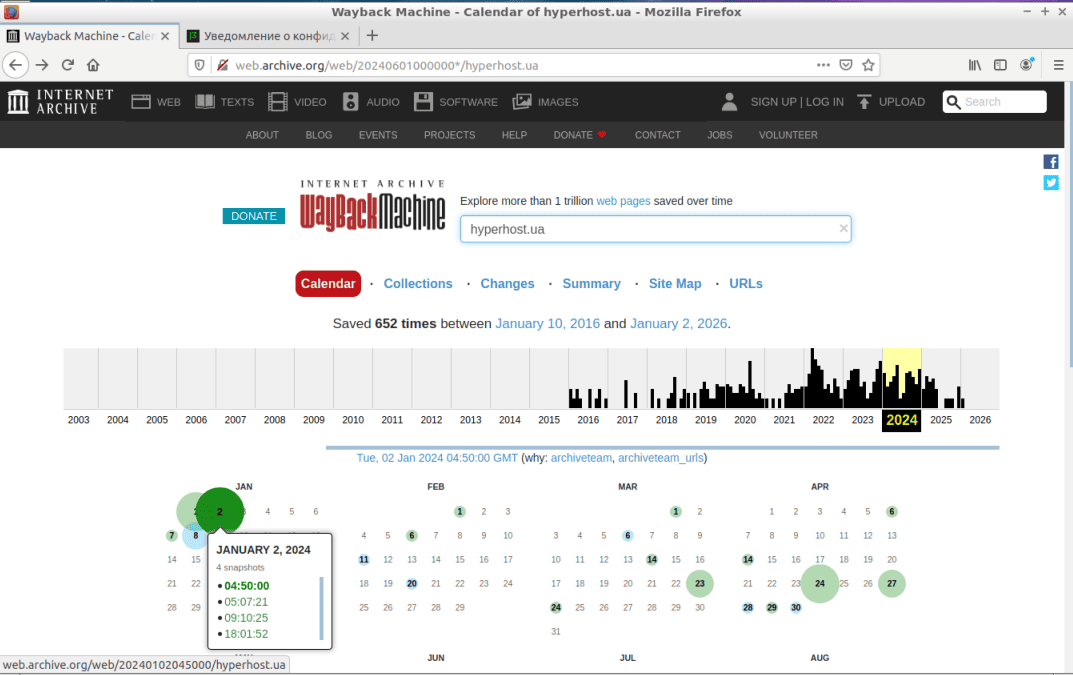
Календар. При натиснутій вкладці і виборі за допомогою миші року, що нас цікавить, на графіку архівування, сервіс відобразить на календарі виділені різними кольорами дати. (див. скріншот). Наявність для певних дат кіл різних розмірів і кольорів свідчить про рівень інтенсивності роботи веб-краулера в цей день і про успішність виконаних операцій зі створення копій. Чим більша площа кола, тим частіше робот звертався до веб-ресурсу. Колір кола показує ступінь успішності операції: синій – ОК, зелений – повернення коду 3xx, червоний і помаранчевий – повернення коду помилок 4xx або 5xx у разі недоступності ресурсу.
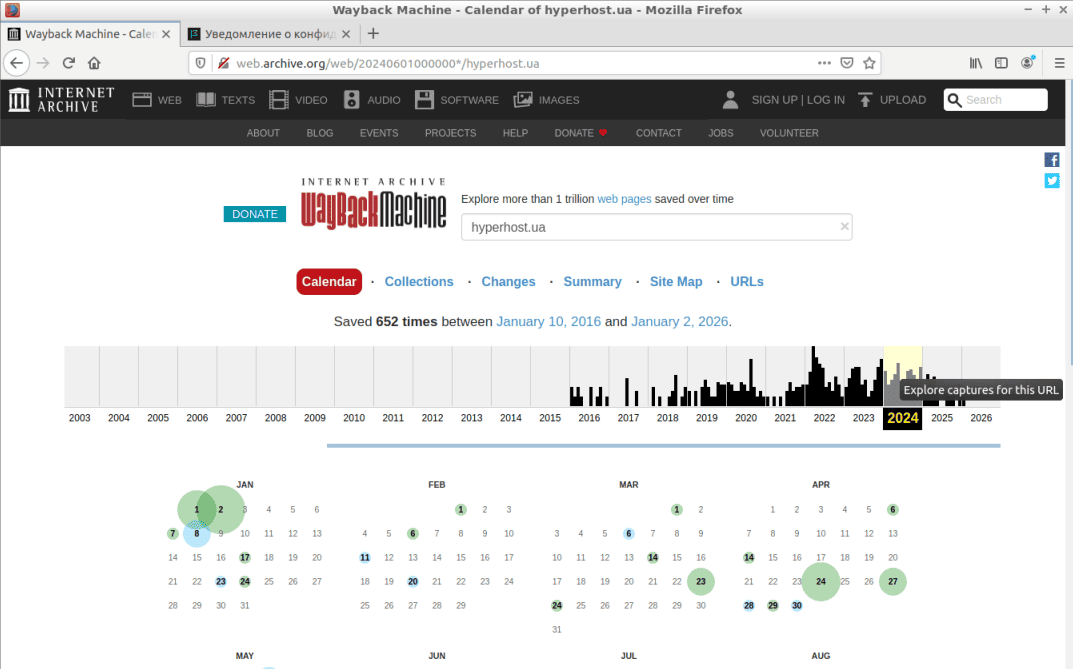
Для прикладу, спробуємо переглянути версію досліджуваного нами сайту станом на 2 січня 2024 року. Для цього достатньо клікнути мишкою на обрану дату в календарі, і в меню, що з'явилося, вибрати час, коли робот відвідував сайт. У нашому випадку – це 4 години 50 хвилин (див. скріншот).
В результаті виконання зазначених дій, сервіс завантажить візуальну частину головної сторінки сайту станом на ранок 2 січня 2024 року (див. скріншот).
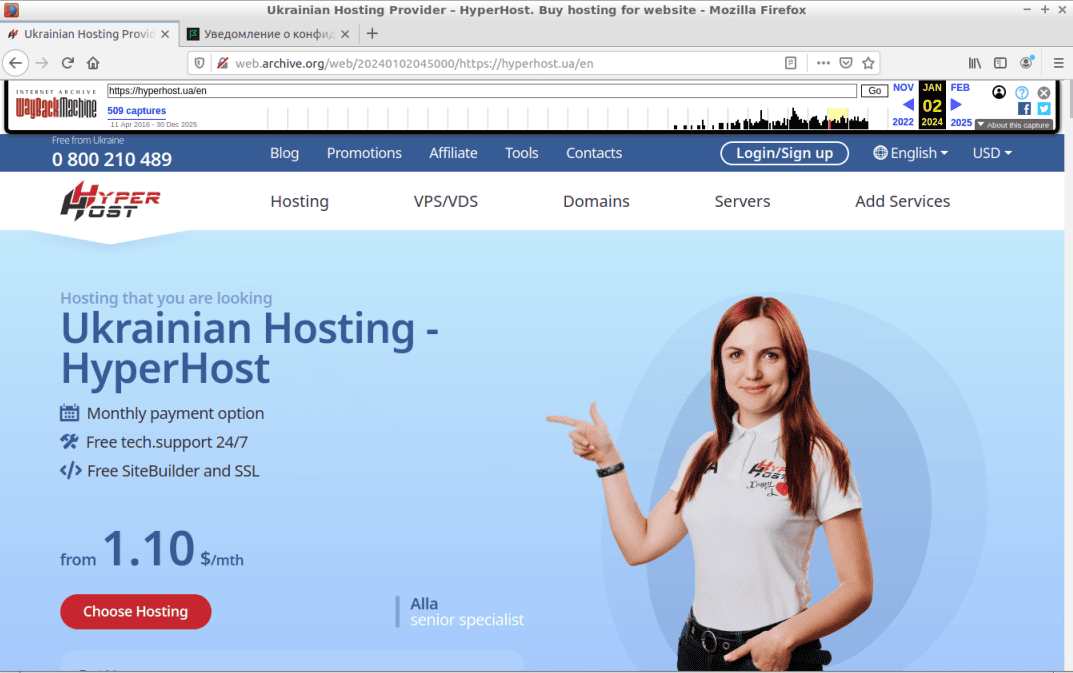
Ми навіть можемо виконати переходи за гіперпосиланнями сторінки, щоб переконатися, що Frontend частина ресурсу повністю збережена і коректно відтворюється з архівної копії.
Колекції. Тут можна отримати доступ до впорядкованих груп контенту досліджуваного сайту або, як кажуть, тематичних колекцій, до яких відносяться зображення різних форматів, відео, документи тощо (див. скріншот).
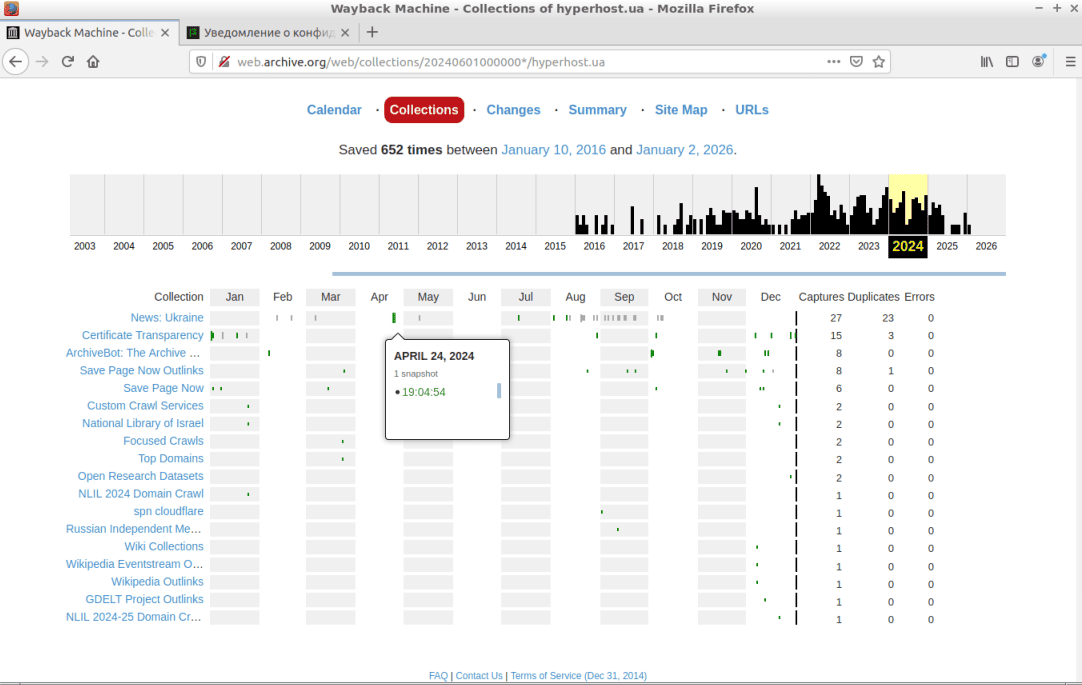
Ми навіть можемо виконати переходи за гіперпосиланнями сторінки, щоб переконатися, що Frontend частина ресурсу повністю збережена і коректно відтворюється з архівної копії.
Колекції. Тут можна отримати доступ до впорядкованих груп контенту досліджуваного сайту або, як кажуть, тематичних колекцій, до яких відносяться зображення різних форматів, відео, документи тощо (див. скріншот).
Підсумкова інформація (Summary). Тут виводиться зведена інформація по історії зміни веб-ресурсу, включаючи статистику по кількості створених копій, активність роботів і багато іншого (див. скріншоти).
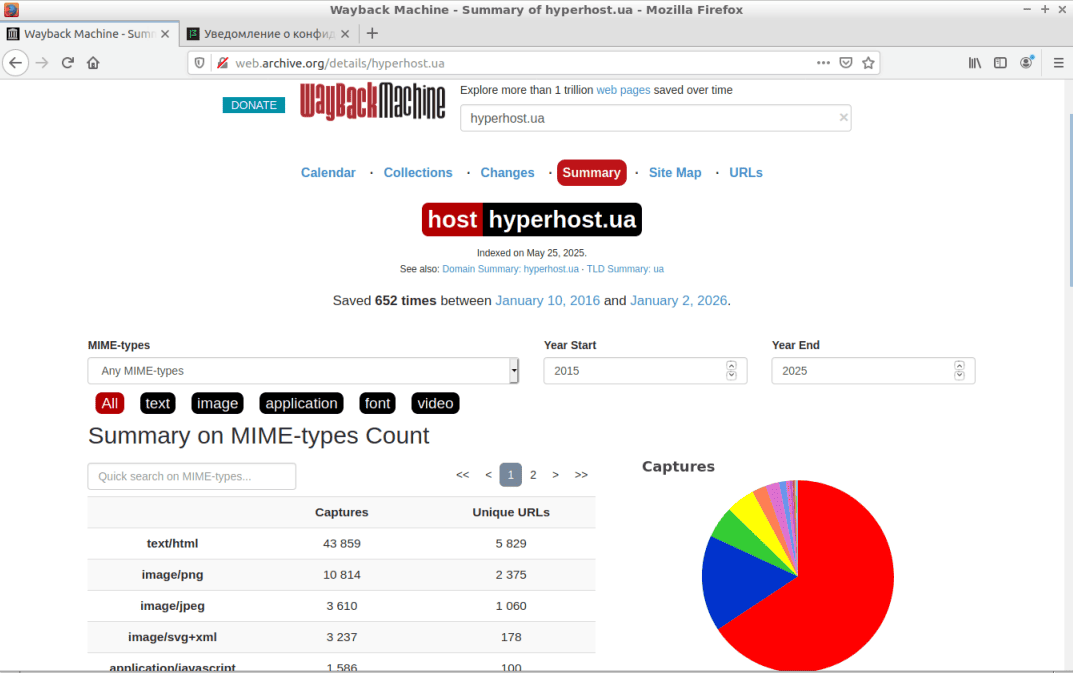
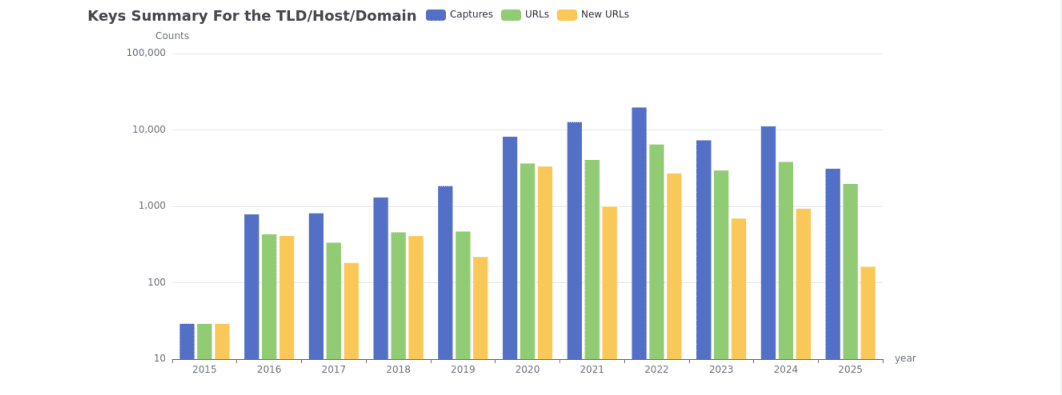
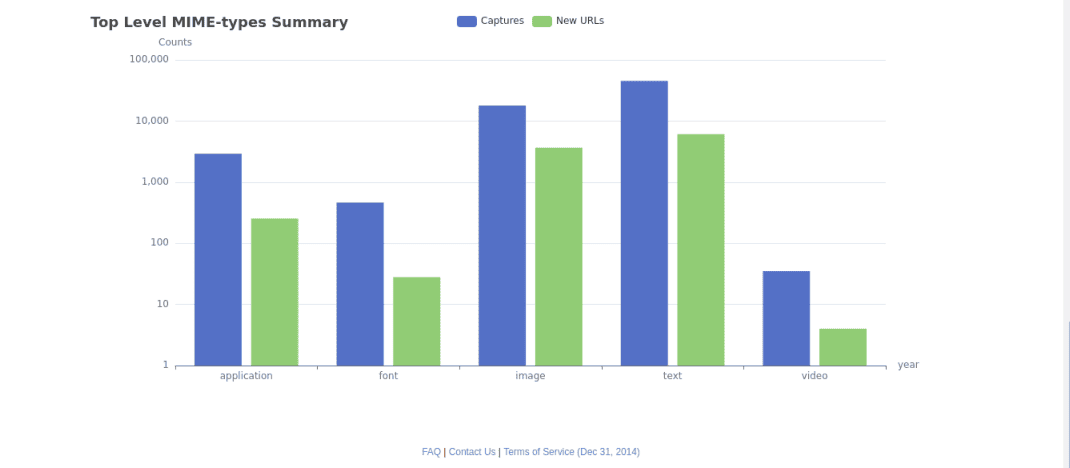
Карта сайту виводить структуровану карту досліджуваного ресурсу, розбитого на розділи і сторінки, що дозволяє легко перейти до потрібного елементу.
URLs зберігає список адрес всіх збережених на сервісі веб-сторінок потрібного ресурсу.
Що реально можна відновити через WebArchive
Як ми вже з'ясували, крім контентної складової веб-ресурсу, сервіс зберігає лише ту частину програмного коду, яка забезпечує його візуалізацію. Це дозволяє в подальшому відновити наступні дані:
Весь статичний контент ресурсу – текстове наповнення, зображення, відео та інші медіадані;
- Структуру HTML-сторінок;
- Базові стилі CSS сторінок;
- Деяку частину коду JavaScript.
Для відновлення зазначених даних можна скористатися одним із таких способів:
- Ручне копіювання кожної веб-сторінки, що відображається;
- Копіювання за допомогою Python-скриптів, що забезпечують автоматизоване завантаження даних із Wayback Machine. Приклади найвідоміших скриптів: Wayback Scraper і wayback-machine-downloader;
- Звернутися до послуг сторонніх служб, наприклад, Archivarix і Wayback Machine Downloader.
Перший із способів є найменш ефективним і може знадобитися лише в разі обмеженої кількості сторінок.
Другий спосіб може виявитися ефективним, але вимагає наявності певних знань і навичок у сфері IT або готовності оплатити послуги IT-фахівця.
Що неможливо відновити через WebArchive
Виходячи з того, що ми вже знаємо про принципи збору та зберігання інформації на сервісі Wayback Machine, можна зробити висновок, що відновленню не підлягають такі дані сайтів:
- Динамічний контент, зокрема, генерований Flash-скриптами;
- Серверні налаштування;
- Налаштування безпеки використовуваної CMS;
- Вся Backend частина ресурсу – CMS, PHP-код сторінок, всі серверні скрипти тощо;
- Структура баз даних, їх налаштування та повний вміст.
Більша частина зазначених даних складає так званий «движок» будь-якого сучасного сайту, без якого він самостійно функціонувати не може. Це означає, що за допомогою сервісу Wayback Machine повне відновлення веб-ресурсу при будь-якій підтримці принципово неможливе.
WebArchive проти резервних копій на хостингу
Ми провели порівняльний аналіз принципів і можливостей збереження резервних копій веб-ресурсів на звичайному хостингу та WebArchive. Його результати наведено в таблиці 1.
Таблиця 1. Порівняльна характеристика засобів резервного копіювання.
|
Характеристика |
Звичайний хостинг |
WebArchive |
|
Періодичність автоматизованого створення копій |
Настроюється користувачем |
Некерований процес з великими періодами копіювання |
|
Повнота копії |
Frontend + Backend + База даних |
Тільки Frontend частина зі статичним контентом |
|
Простота і швидкість відновлення |
Просто і максимально швидко за допомогою вбудованих засобів управління хостингом (ISPManager, cPanel, DirectAdmin тощо) |
Складно. Вимагає наявності спеціальних скриптів, навичок IT-фахівця або фінансових витрат на оплату робіт з відновлення сторонніми службами. |
|
Гарантії збереження |
Гарантовано договором з хостинг-провайдером |
Немає гарантій. Керується внутрішніми директивами організації Internet Archive. |
|
Рекомендації щодо використання для відновлення даних |
Для повного відновлення будь-якого веб-ресурсу, в тому числі з конфіденційною інформацією |
Для відновлення статичного контенту та структури невеликої кількості веб-сторінок |
Коли WebArchive корисний власнику сайту
Перелічимо випадки, коли використання сервісу WebArchive може стати дуже корисним для власника:
- При редизайні, міграції або розробці нового стилю сайту – порівняння ранніх версій дизайну між собою допоможе сформувати оптимальний варіант візуального образу веб-ресурсу. Це найбільш підійде для сайтів-візиток людей творчих професій або офіційних представництв компаній / державних органів;
- Для аналізу старого контенту і створення нових рішень юзабіліті для залучення і утримання своїх майбутніх клієнтів. Це, як не можна до речі, підійде для Інтернет-магазинів, сайтів оптових продажів і біржових трейдерів і т. д.;
Для SEO-аналізу змін, внесених на сайт; - Для термінового відновлення випадково видаленої сторінки невеликого веб-ресурсу;
- Для вивчення історії розвитку ресурсу-довгожителя: інтернет-видання, сайту інформаційно-пізнавального характеру та інших подібних.
Обмеження та мінуси WebArchive
Вкажемо на деякі обмеження, пов'язані з використанням сервісу WebArchive. Ось ці обмеження:
Неможливість використання сайтами, що містять конфіденційні дані користувачів та іншу секретну інформацію. У цьому випадку власник ресурсу повинен звернутися до адміністрації сервісу із заявою про необхідність його видалення з загальнодоступної бази сервісу та заборони його сканування.
Дані можуть бути застарілими. Це пов'язано з нерегулярністю створення копій, що може призвести до відсутності в базі більш нових версій сайту. Це знижує практичну цінність сервісу, як «хранителя» історії життя ресурсів.
Відсутність гарантій на збереження сайту, що може призвести до повної відсутності в базі його архівних копій. Не всі сайти можуть потрапити в базу сервісу. Це пов'язано з величезною кількістю веб-сторінок в межах загальнодоступної мережі, що змушує організаторів сервісу вводити функцію вибірковості для веб-краулерів при виборі «кандидатів» на збереження. Туди тепер можуть потрапити тільки добре відвідувані сайти з великою кількістю перехресних посилань і деякими іншими характеристиками, які організатори сервісу повністю не розкривають інтернет-спільноті.
Обмежені можливості і складність відновлення втрачених даних. Обмеження випливає з того, що сервіс зберігає лише ту частину коду ресурсу, яка відповідає за візуалізацію. Весь інший код, а також структуру БД відновити неможливо. Складність відновлення пов'язана з необхідністю наявності спеціальних скриптів і / або витратами на послуги фахівців.
Висновок
Таким чином, ми можемо зробити висновок, що сервіс WebArchive, як платформа резервного копіювання, є лише додатковим інструментом і підходить для відновлення лише деяких видів даних. І тому він у жодному разі не може бути використаний як повноцінний засіб створення бекапів. Для цих цілей краще вибрати звичайний хостинг-майданчик з величезними можливостями з управління резервним копіюванням і гарантіями щодо забезпечення безпеки збережених копій.






