Что такое Вебархив (WebArchive) - реально ли восстановить свой сайт из архива
Нередко случаются ситуации, когда необходимо получить устаревшую версию сайта, например, для нужд SEO-оптимизации или в случае повреждения или случайном удалении веб-страницы ресурса. На этот случай в сети можно получить совет воспользоваться возможностями всемирно известного сервиса WebArchive, который, как принято считать, хранит текущие версии всех сайтов вместе со всеми предыдущими изменениями. Иногда это действительно может помочь восстановить утраченные данные, например, содержимое удалённой HTML-страницы. Однако во многих других случаях этот способ может не подойти, поскольку WebArchive сохраняет лишь моментальные снимки веб-страниц сайтов, которые не годятся для их полноценного восстановления. В связи с этим, рассмотрим возможности сервиса по восстановлению утраченных данных, а также его ограничения.
Что такое Вебархив (WebArchive)
Веб-архив сайтов или Web Archive – это одно из основных направлений деятельности американской некоммерческой организации Internet Archive по сохранению истории Интернет-сети.
Проект реализован на базе онлайн-сервиса Wayback Machine, что переводится как Машина времени, созданного на базе языков Java и Python. Он обеспечивает выполнение двух основных задач:
- Сбор и хранение снапшотов веб-страниц со всей сети;
- Предоставление общедоступного интерфейса для доступа к сохранённым данным.
Web Archive не является традиционным хостингом или площадкой для хранения бекапов (backup), поскольку бекапы сайтов, как таковые, им не создаются, а лишь моментальные снимки или снапшоты (snapshot) их визуальной части. Это позволяет впоследствии воспроизвести видимую часть веб-ресурса, что и было основной целью создателей проекта.
К ноябрю 2025 года сервисом была каталогизирована и сохранена коллекция веб-страниц, состоящая из более чем 1 триллиона экземпляров. И этот процесс никогда не прекращается, за исключением редких периодов, связанных с восстановлением сервиса после хакерских атак, как, например, было в октябре 2024 года во время продолжительной DDoS атаки.
Как WebArchive сохраняет страницы сайтов
Пополнение веб-архива осуществляется веб-краулерами или ботами, входящими в состав Wayback Machine, которые работают по аналогии с поисковыми роботами. Попав на очередную веб-страницу, они последовательно обходят все находящиеся на ней гиперссылки, формируя при этом сеть доступных веб-узлов для пополнения коллекции архива. Робот останавливается только в случае превышения установленного лимита.
Отсканированные роботами копии веб-страниц автоматически конвертируются в файлы формата WARC (Web ARChive) размером 100 МБ и сохраняются на серверах Internet Archive, размещённых в США, Египте и Нидерландах. После этого архивные снимки веб-ресурсов становятся доступными через интерфейс Wayback Machine в формате HTML с поддержкой технологий JavaScript (интерактивность), и CSS (стили страниц).
Инициировать процесс сохранения веб-страниц ресурса может и обычный пользователь сети, введя в специальной форме на главной странице сервиса адрес сайта, как, например, показано ниже на скриншоте. В этом случае URL ресурса будет сохранён системой и впоследствии использован роботом для занесения сайта в архив.
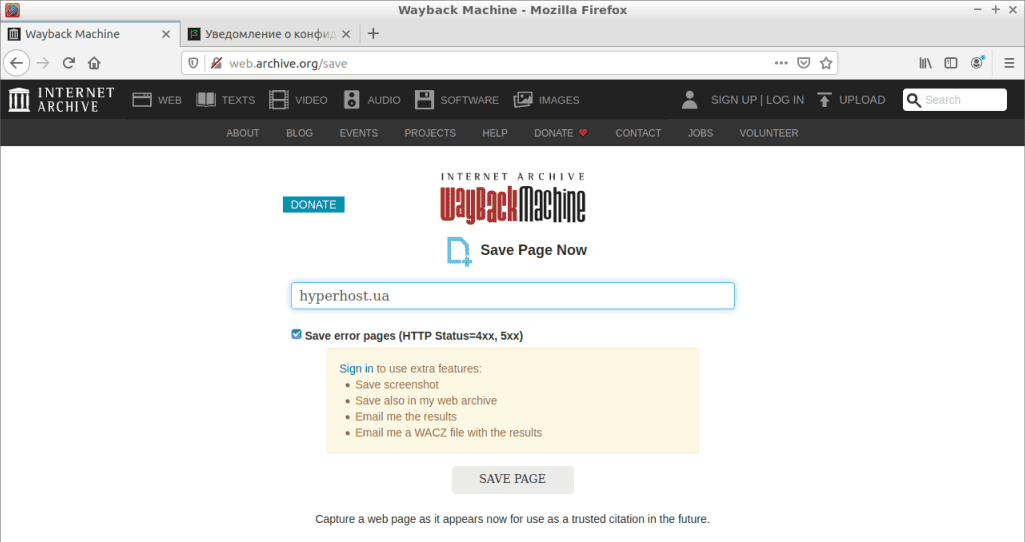
Как посмотреть старую версию сайта через WebArchive
Замечательной особенностью сервиса является фиксация в общедоступной базе цепочки версий одного и того же сайта, что позволяет впоследствии использовать эту информацию в разных целях, например, совершенствования дизайна, анализа действий конкурентов, SEO-оптимизации, восстановления данных и во многих других случаях.
Чтобы просмотреть старую версию сохранённого в базе сервиса веб-ресурса, нужно зайти на главную страницу сервиса Wayback Machine и в строке поиска, расположенной под главным меню страницы, ввести адрес нужного ресурса и нажать Enter (см. скриншот).
При этом инициируется загрузка страницы сервиса по выбранному ресурсу, на которой будет выведен график архивации сайта за весь период его «жизни», а также календарь создания копий для выбранного сайта. В верхней части загруженной страницы находится несколько функциональных вкладок: Календарь, Коллекции, Изменения, Итоговая информация, Карта сайта и URLs (см. скриншот). Рассмотрим назначение этих вкладок подробнее.
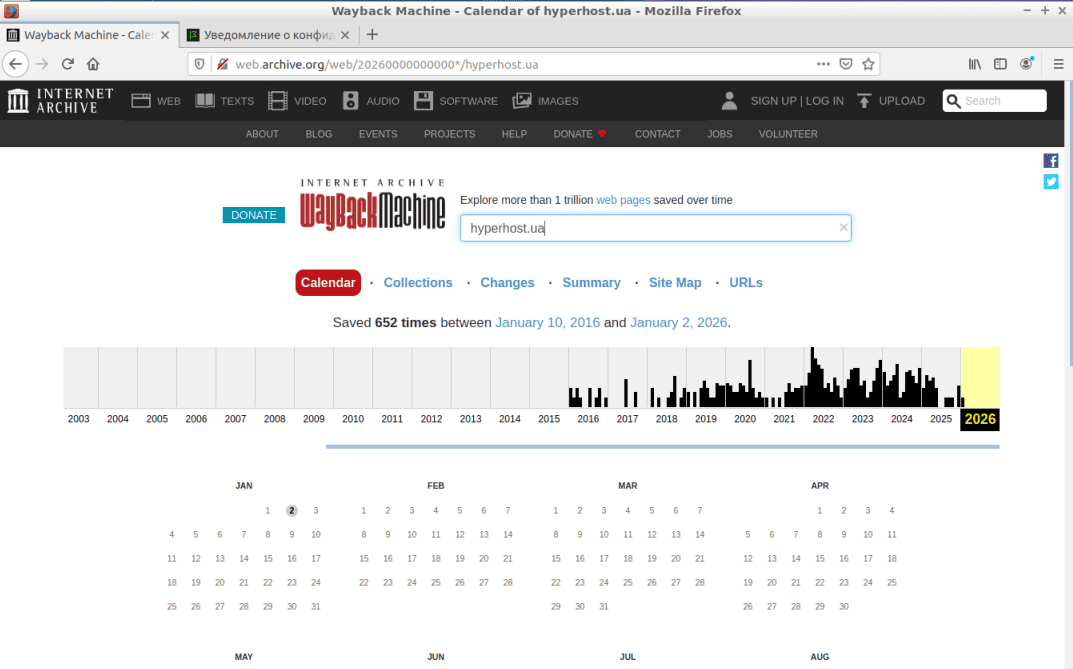
Календарь. При нажатой вкладке и выборе с помощью мыши интересующего нас года на графике архивации, сервис отобразит на календаре выделенные разными цветами даты. (см. скриншот). Наличие для определённых дат кругов разных размеров и цвета говорит об уровне интенсивности работы веб-краулера в этот день и об успешности выполненных операций по созданию копий. Чем больше площадь круга, тем чаще робот обращался к веб-ресурсу. Цвет круга показывает степень успешности операции: синий – ОК, зелёный – возврат кода 3xx, красный и оранжевый – возврат кода ошибок 4xx или 5xx в случае недоступности ресурса.
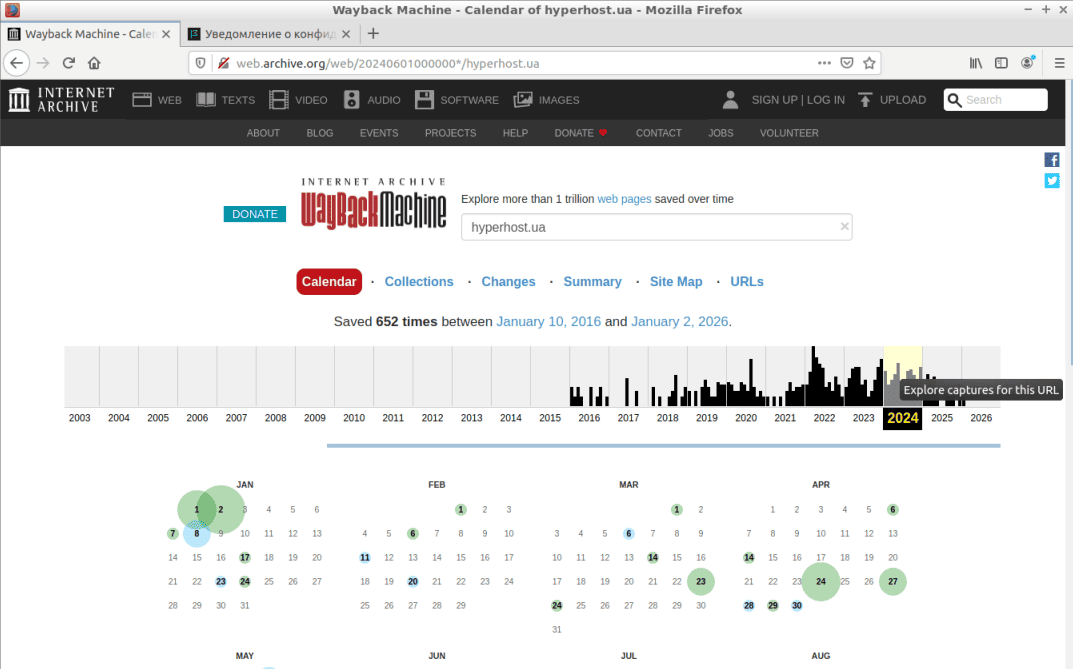
Для примера, попытаемся просмотреть версию исследуемого нами сайта по состоянию на 2 января 2024 года. Для этого достаточно кликнуть мышью по выбранной дате в календаре, и в появившемся меню выбрать время, когда робот посещал сайт. В нашем случае – это 4 часа 50 минут (см. скриншот).
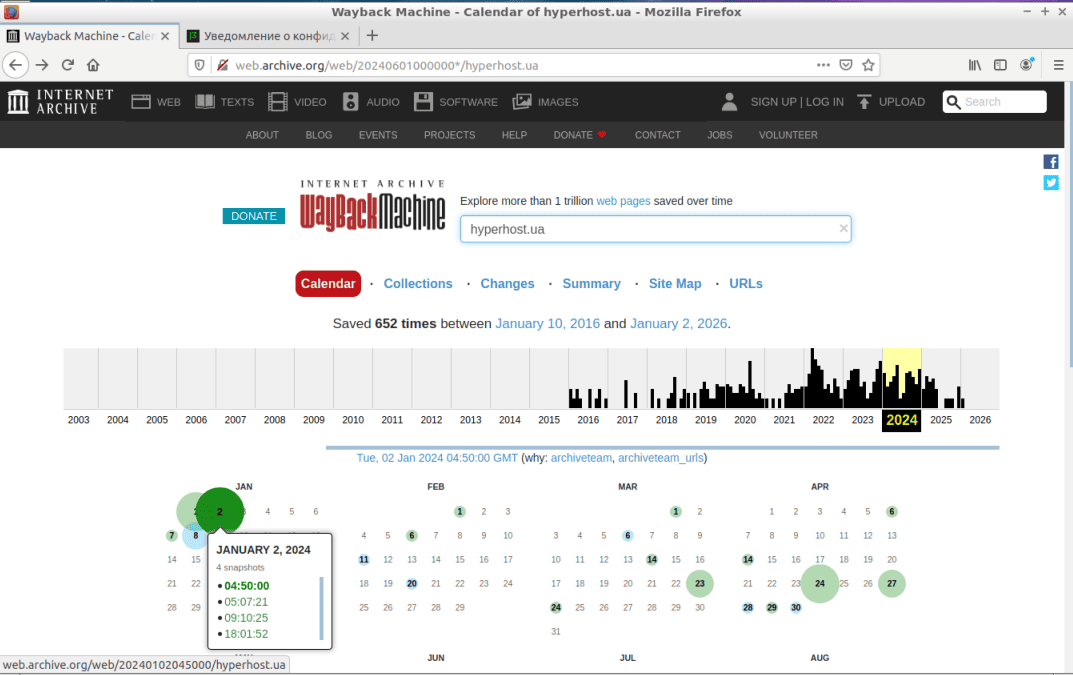
В результате выполнения указанных действий, сервис загрузит визуальную часть главной страницы сайта состоянием на утро 2 января 2024 года (см. скриншот).
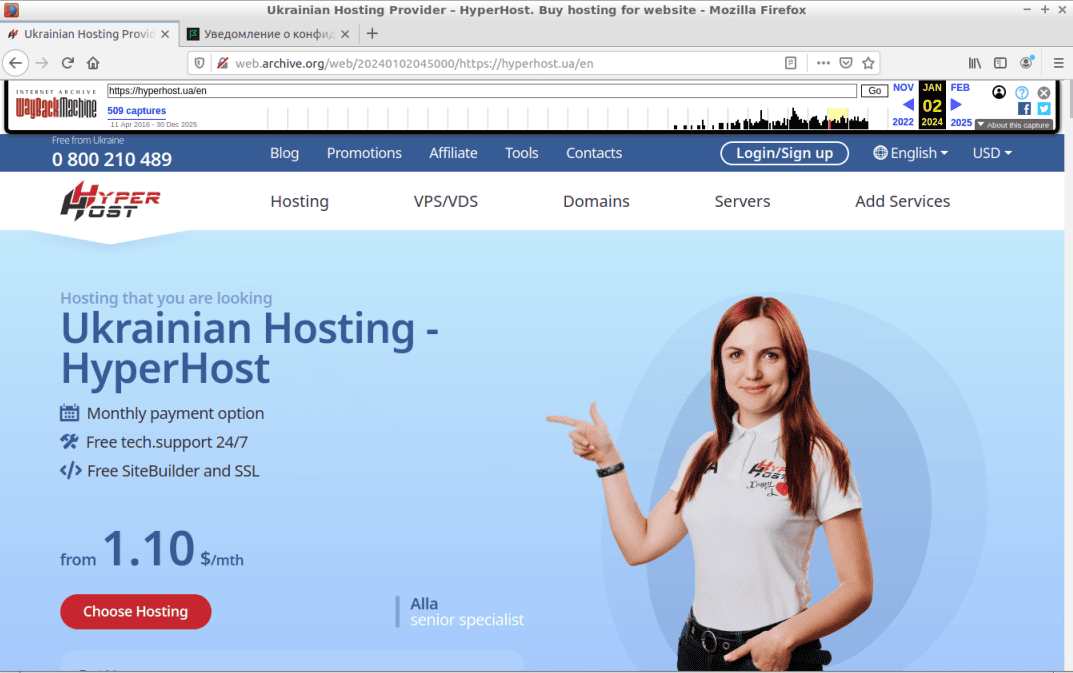
Мы даже можем выполнить переходы по гиперссылкам страницы, чтобы убедиться, что Frontend часть ресурса полностью сохранена и корректно воспроизводится из архивной копии.
Коллекции. Здесь можно получить доступ к упорядоченным группам контента исследуемого сайта или, как говорят, тематическим коллекциям, к которым относятся изображения разных форматов, видео, документы и т. д. (см. скриншот).
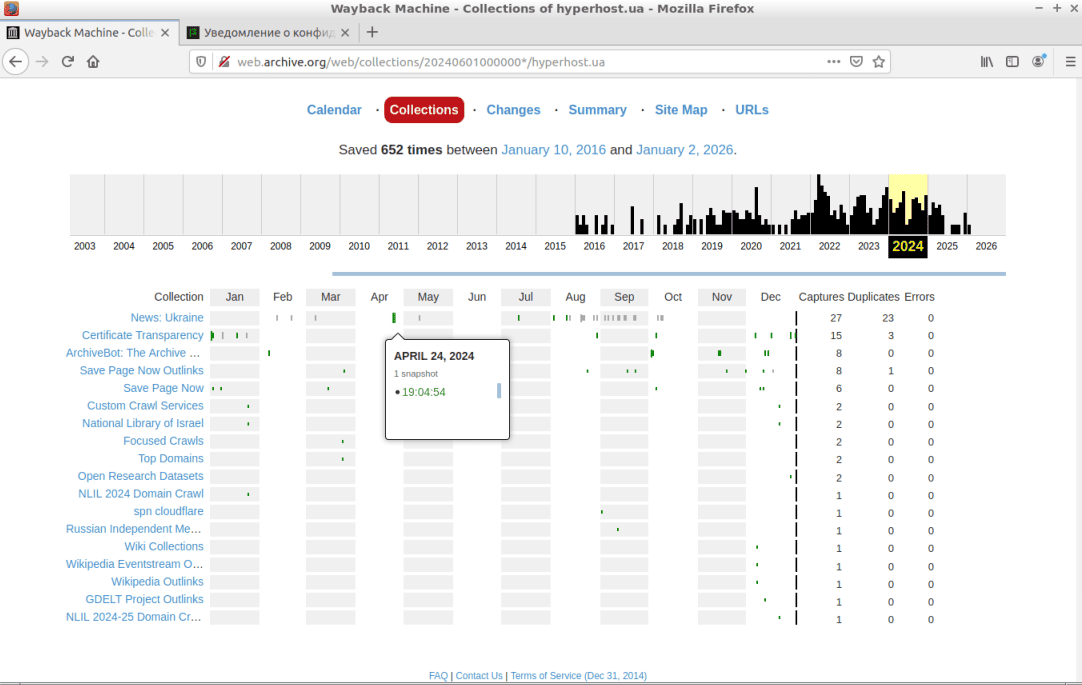
Мы даже можем выполнить переходы по гиперссылкам страницы, чтобы убедиться, что Frontend часть ресурса полностью сохранена и корректно воспроизводится из архивной копии.
Коллекции. Здесь можно получить доступ к упорядоченным группам контента исследуемого сайта или, как говорят, тематическим коллекциям, к которым относятся изображения разных форматов, видео, документы и т. д. (см. скриншот).
Итоговая информация (Summary). Здесь выводится сводная информация по истории изменения веб-ресурса, включая статистику по количеству созданных копий, активность роботов и многое другое (см. скриншоты).
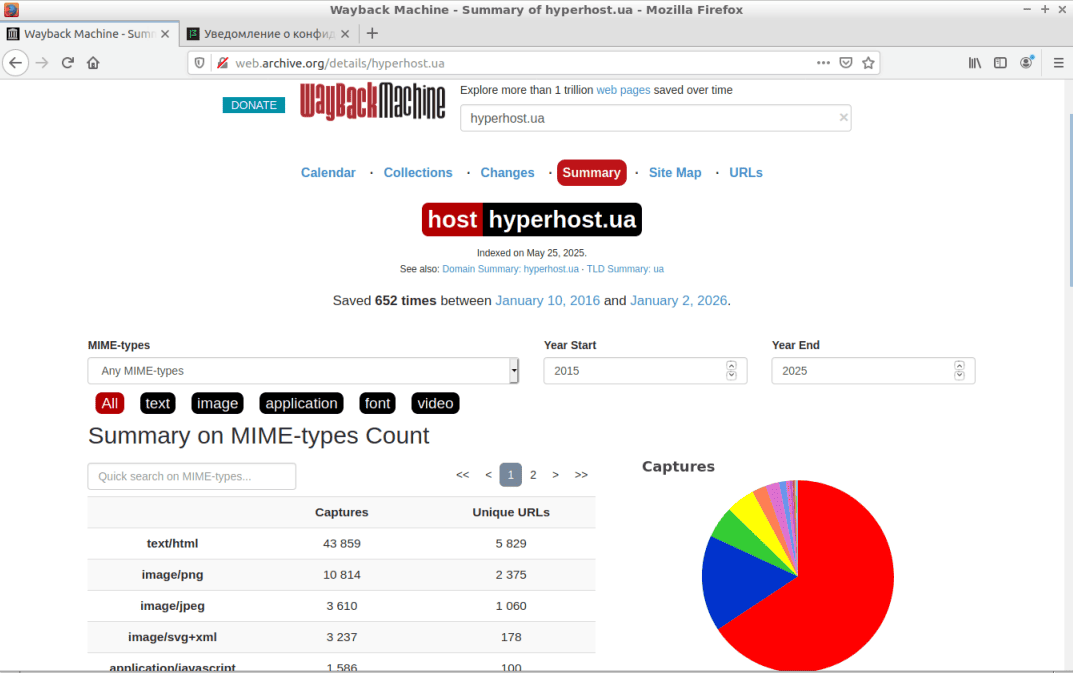
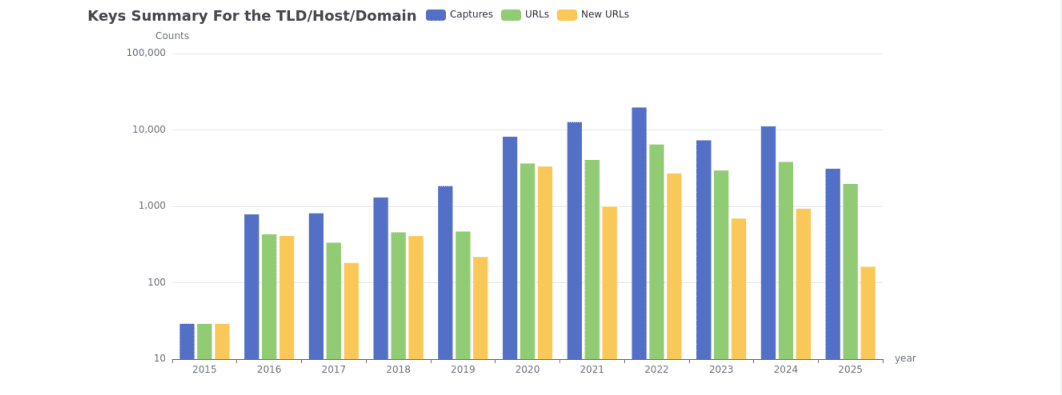
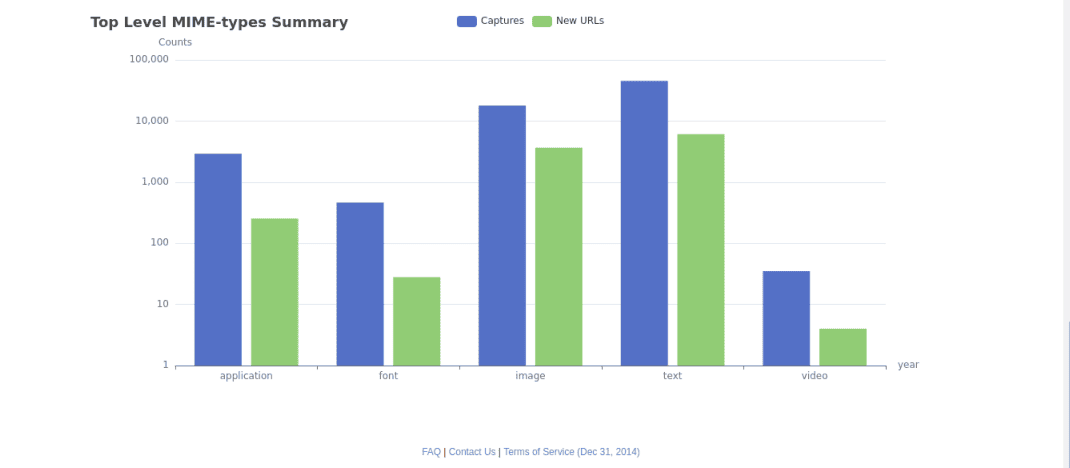
Карта сайта выводит структурированную карту исследуемого ресурса, разбитого на разделы и страницы, что позволяет легко перейти к нужному элементу.
URLs хранит список адресов всех сохранённых на сервисе веб-страниц нужного ресурса.
Что реально можно восстановить через WebArchive
Как мы уже выяснили, кроме контентной составляющей веб-ресурса, сервис сохраняет лишь ту часть программного кода, которая обеспечивает его визуализацию. Это позволяет в дальнейшем восстановить следующие данные:
- Весь статический контент ресурса – текстовое наполнение, изображения, видео и другие медиаданные;
- Структуру HTML-страниц;
- Базовые стили CSS страниц;
- Некоторую часть кода JavaScript.
Для восстановления указанных данных можно воспользоваться одним из следующих способов:
- Ручное копирование каждой отображаемой веб-страницы;
- Копирование с помощью Python-скриптов, обеспечивающих автоматизированную загрузку данных с Wayback Machine. Примеры наиболее известных скриптов: Wayback Scraper и wayback-machine-downloader;
- Обратиться к услугам сторонних служб, например, Archivarix и Wayback Machine Downloader.
Первый из способов является самым неэффективным и может понадобиться лишь в случае ограниченного количества страниц.
Второй способ может оказаться эффективным, но требует наличия известных знаний и навыков в области IT или быть готовым к оплате услуг IT-специалиста.
Третий способ эффективный и наиболее приемлемый, однако, может оказаться весьма затратным в зависимости от объёмов закачанной информации.
Что невозможно восстановить через WebArchive
Исходя из того, что мы уже знаем о принципах сбора и хранения информации на сервисе Wayback Machine, можно сделать вывод, что восстановлению не подлежат следующие данные сайтов:
- Динамический контент, в частности, генерируемый Flash-скриптами;
- Серверные настройки;
- Настройки безопасности используемой CMS;
- Вся Backend часть ресурса – CMS, PHP-код страниц, все серверные скрипты и т. д.;
- Структура баз данных, их настройки и полное содержимое.
Большая часть указанных данных составляют, так называемый, «движок» любого современного сайта, без которого он самостоятельно функционировать не может. Это означает, что с помощью сервиса Wayback Machine полное восстановление веб-ресурса при любой поддержке принципиально невозможно.
WebArchive vs резервные копии на хостинге
Мы провели сравнительный анализ принципов и возможностей по сохранению резервных копий веб-ресурсов на обычном хостинге и WebArchive. Его результаты сведены в Таблицу 1.
Таблица 1. Сравнительная характеристика средств резервного копирования.
|
Характеристика |
Обычный хостинг |
WebArchive |
|
Периодичность автоматизированного создания копий |
Настраиваемая пользователем |
Неуправляемый процесс с большими периодами копирования |
|
Полнота копии |
Frontend + Backend + База данных |
Только Frontend часть со статическим контентом |
|
Простота и скорость восстановления |
Просто и максимально быстро с помощью встроенных средств управления хостингом (ISPManager, cPanel, DirectAdmin и т. д.) |
Сложно. Требует наличия специальных скриптов, навыков IT-специалиста или финансовых затрат на оплату работ по восстановлению сторонними службами |
|
Гарантии сохранности |
Гарантировано договором с хостинг-провайдером |
Нет гарантий. Управляется внутренними директивами организации Internet Archive |
|
Рекомендации к использованию для восстановления данных |
Для полного восстановления любого веб-ресурса, в том числе с конфиденциальной информацией |
Для восстановления статического контента и структуры небольшого количества веб-страниц |
Когда WebArchive полезен владельцу сайта
Перечислим случаи, когда использование сервиса WebArchive может стать весьма полезным для владельца:
- При редизайне, миграции или разработке нового стиля сайта – сравнение ранних версий дизайна между собой поможет сформировать оптимальный вариант визуального образа веб-ресурса. Это наиболее подойдёт для сайтов-визиток людей творческих профессий или официальных представительств компаний / государственных органов;
- Для анализа старого контента и создания новых решений юзабилити для привлечения и удержания своих будущих клиентов. Это, как нельзя кстати, подойдёт для Интернет-магазинов, сайтов оптовых продаж и биржевых трейдеров и т. д.;
- Для SEO-анализа внесённых в сайт изменений;
- Для срочного восстановления случайно удалённой страницы небольшого веб-ресурса;
- Для изучения истории развития ресурса-долгожителя: Интернет-издания, сайта информационно-познавательного характера и других подобных.
Ограничения и минусы WebArchive
Укажем на некоторые ограничения, связанные с использованием сервиса WebArchive. Вот эти ограничения:
Невозможность использования сайтами, содержащими конфиденциальные данные пользователей и другую секретную информацию. В этом случае владелец ресурса должен обратиться к администрации сервиса с заявлением о необходимости его удаления из общедоступной базы сервиса и запрета его сканирование.
Данные могут быть устаревшими. Это связано с нерегулярностью создания копий, что может привести к отсутствию в базе более новых версий сайта. Это снижает практическую ценность сервиса, как «хранителя» истории жизни ресурсов.
Отсутствие гарантий на сохранение сайта, что может привести к полному отсутствию в базе его архивных копий. Не все сайты могут попасть в базу сервиса. Это связано с огромным количеством веб-страниц в пределах общедоступной сети, что вынуждает организаторов сервиса к введению функции избирательности для веб-краулеров при выборе «кандидатов» на сохранение. Туда теперь могут попасть только хорошо посещаемые сайты с большим количеством перекрёстных ссылок и некоторыми другими характеристиками, полностью не открываемые Интернет-сообществу организаторами сервиса.
Ограниченные возможности и сложность восстановления утерянных данных. Ограничение исходит из того, что сервис сохраняет лишь ту часть кода ресурса, которая отвечает за визуализацию. Весь другой код, а также структуру БД восстановить невозможно. Сложность восстановления связана с необходимостью наличия специальных скриптов и / или затратами на услуги специалистов.
Заключение
Таким образом, мы можем сделать вывод, что сервис WebArchive, как платформа резервного копирования, является лишь дополнительным инструментом и подходит для восстановления лишь некоторых видов данных. И поэтому он ни в коем случае не может быть использован в качестве полноценного средства создания бекапов. Для этих целей лучше выбрать обычную хостинг-площадку с огромными возможностями по управлению резервным копированием и гарантиями по обеспечению безопасности хранимых копий.






